
Months ago, I wrote an introductory article on the world of composite metrics, the all-in-one figures that attempt to measure a player’s total contributions in a single number. Today, I’ll expand on the concepts discussed in that post to examine the mathematical and philosophical structures of certain metrics and determine the validity of the sport’s one-number evaluators.
What makes a good metric? The expected response is likely a mixture of how the leaderboard of the statistic aligns with the viewer’s personal rankings and whether the metric includes non-box data for its defensive component. While this may pick apart some of the sport’s “better” metrics, it won’t separate the “good” from the “great.” The advancements of the game’s one-number metrics are far greater than given credit for, and a player’s situational value on his own team can be captured near-perfectly. It’s the nuances of individual metrics that create poor, good, or great measurements.
—
Player Efficiency Rating
PER was the original “godfather” metric in the NBA, created by The Athletic senior columnist, John Hollinger. PER, according to him, “… sums up all a player’s positive accomplishments, subtracts the negative accomplishments, and returns a per-minute rating of a player’s performance.”[1] Although one of the leading metrics of its time, PER receives strong criticism nowadays for its box-only approach. This may seem unjustified, as metrics like Box Plus/Minus are highly regarded with its box-only calculations. PER differentiates itself from a regression model like BPM in that it’s largely based on theory: expected point values.
Basketball-Reference‘s mock calculations of PER include a factor called “VOP.” Although the author of the article intentionally leaves it vague, I’ve interpreted this to mean “value of possession.” The resulting factor is an estimate of the average number of points scored per possession in a given season. From there, different counting statistics are weighed to the “expected” degree to which they enhance or diminish the point value of a possession. Due to the large inferencing and supposed values of box score statistics, the descriptive power of PER is limited, and the metric is largely recognized as outdated. However, PER provides an accurate and representative look into the theories and values of the early Data-Ball Era.
Win Shares
Basketball-Reference visitors are familiar with Win Shares. Daniel Myers, the developer of the metric, states it “… attempts to divvy up credit for team success to the individuals on the team.” [2] Contrary to most one-number metrics, Win Shares don’t attempt to measure a player’s value on an “average” team, and rather allocate a team’s success among its players. Myers took a page out of Bill James’s book with his Win Shares system, which originally set three “Win Shares” equal to one team win. This meant a team with 42 wins had a roster that accrued roughly 126 “Win Shares.” The ratio was eventually changed to 1:1, so nowadays, a team with 42 wins will have a roster that accumulated roughly 42 Win Shares.
Myers based his offensive points produced and defensive points allowed on a player-rating system developed by Dean Oliver in his novel, Basketball on Paper. The components, Offensive/Defensive Ratings, are highly-complex box score solutions to determine the number of points added or subtracted on either end of the floor. With these figures for a player, Myers then calculates what’s referred to as “marginal offense/defense,” or the number of points a player accounted for that contributed to winning; ones that weren’t negated in the general scheme of a game. Marginal offense and defense are then divided by the number of points the team required to win a game that season. This creates individual Offensive and Defensive Win Shares measurements as well as total Win Shares.
The Win Shares system, like PER, was one of the strongest metrics of its time. It was one of the first widespread all-in-one metrics that was able to accurately distribute a team’s success among its players: one of the original holy-grail questions in basketball. The main gripe on the Win Shares system is its use of Oliver’s player ratings, which are widely disdained for not passing the criteria listed earlier: the typical “stat-test.” Oliver’s ratings are, in truth, some of the very best metrics that solely use counting statistics; it’s simply displayed in the wrong format. As Oliver states, his Offensive Rating estimate “… the number of points produced by a player per hundred total individual possessions.” [3] We can substitute “allowed” for “produced” to describe his Defensive Rating. The key words in Oliver’s definition are “total individual possessions.” His ratings measure the number of points produced/allowed every 100 possessions a player is directly involved in.
Resultantly, Oliver’s ratings are best taken as a percentage of individual possessions, or the number of possessions per 100 in which a player is “directly” involved (assisting, shooting, offensive rebounding, turning over). If a player has an ORtg of 110 with an offensive load of 40, his “adjusted” ORtg would be 44, which represents 44 points produced per 100 team possessions rather than individual possessions. I make this remark to remind us all that metrics can be improved upon, added context to, and revitalized. If Myers were to develop a “Win Shares 5.0,” it may be worth examining to “adjust” Oliver’s playing ratings to a less role-sensitive form. The Win Shares system is notably superior to PER in the comparative applications, with far more descriptive power. It may not rank at the very top of the metric echelons, but Win Shares are a fair and moderately-accurate representation of a player’s value to his own team.
—
History of Plus/Minus Data
PER and Win Shares are two of the most successful and/or widespread metrics that quantify impact with expected values, but this ideology slowly began to disappear. What’s the value of a rebound? How many points of an assisted field goal should be credited to the passer? Is a point even really worth one point? These questions of extremely ambiguous and unanswered natures led statisticians to a new viewpoint on quantifying impact: plus/minus data. This involved measuring a team’s performance with a player on the floor rather than weighing the player’s counting statistics. This new ideology, in theory, is the holy-grail perspective we’d need to perfectly pinpoint a player’s value, but statisticians were once again met with interference.
Traditional Plus/Minus (abbreviated as +/-) measures the team’s Net Rating, point differential extrapolated to 100 possessions, with a player on the floor. But as the statistically-inclined are familiar with, Plus/Minus (also known as OnCourt +/-) is a deceptive measure of value. Poorer players on great teams that faced poor opponents can have massively inflated scores, while great players on poor teams that faced great competition can have dramatically deflated scores. Resultantly, the application of Plus/Minus was a mostly fruitless beginning for plus/minus data, but that didn’t prevent further advancements. With the main deficiency of Plus/Minus being the lack of teammate and opponent factors, there was a clear path to improving on the ideas of plus/minus data.
WINVAL, a software developed by Jeff Sagarin and Wayne Winston, drew players’ Plus/Minus scores from all of their possessions to evaluate a given player’s impact on different lineups. The system created the building blocks to commence “Adjusted” Plus/Minus (APM), a statistic that takes a player’s Plus/Minus from all of his possessions and accounts for the strengths of opponents and teammates. Without delving too deep into the mathematical processes, APM is drawn from a system of linear equations that includes the home team’s Net Rating during a given stint (one stretch of possessions in which no substitutions are made) as the response variable, the Plus/Minus scores for players as explanatory variables, and recognition as to whether a given player is on the home or away team or whether they’re in the game or not. This gives the calculator the ability to approximate beta-values that results from the series, that being APM in a given game.
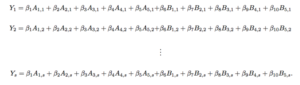
APM “should” have been the holy-grail statistic the world was looking for. It was clear that assigning expected values to counting statistics would nearly always fail, and this new measurement captures changes in the scoreboard without having to distribute credit across different court actions. But (the trend is becoming more and more apparent here) there were still deficiencies with APM that hindered its descriptive power. Namely, it was very unstable, wavering from year-to-year. Its scores also had massive disparities, with excessive amounts of outliers. Dan Rosenbaum was one of, if not the, first to outline an algorithm for APM, and the top player from 2003 to 2004 was Kevin Garnett (unsurprisingly) at +19.3 (surprisingly). We now know even the greatest players in the most inflated situations are rarely worth +10 points to their team, let alone +20 points.
Jeremias Engelmann, one of the greatest basketball statisticians ever, created “Regularized” APM (“RAPM”) to reduce these poorer effects, another being multicollinearity. If two or more players spend a lot of their time on the court together, they’ll face equally-good opponents and play with equally-good teammates, and APM wouldn’t know to allocate team credit any differently, even between players with great gaps in talent. The mathematically-inclined are most likely associating Tikhonov regularization, or ridge regression, as the primary method to overturn these effects. A ridge regression essentially removes the effects of multicollinearity and “punishes” outliers, regressing them closer to the mean. This process largely improves the massive errors present in APM and paints a far clearer picture of the impact a player has in a given system. Engelmann not only created the closest statistic to a holy-grail metric we have today but further improved its descriptive power.
Basketball statistics are often associated and influenced by Bayesian inferencing; namely, the use of priors alongside pure measurements to improve year-to-year accuracy and validity. This could be, for example, blending RAPM with the box score, a traditionally-valued set of counting statistics. Engelmann, however, was credited with partiality to previous data in his “Prior-Informed” RAPM (“PI RAPM“). With three or more seasons under its belt, perhaps even just one, PI RAPM is the best measurement we have a player’s value to his team. It not only includes the philosophical perfections of pure APM, but the mathematical validity of RAPM and the benefits of a player’s past to deliver the most valid impact metric we have today. Engelmann doesn’t update his PI RAPM leaderboard often, having last posted a full leaderboard in 2017 (likely due to focus on another one-number metric), but his contributions to improving APM in the 2000s led way to the revolution we recognize as a heap of impact metrics, each claiming importance among its competitors.
Regression Models
With Engelmann PI RAPM either proprietary or deep underground, how can we find precise measurements of a player’s value nowadays? Statisticians around the globe have taken advantage of the linear relationships between certain statistics and a player’s impact on the scoreboard to create regression models that approximate long-term RAPM (rather than short-term due to the aforementioned instability of small samples). The components of each metric are what make them different, but the end-goal remains the same: to approximate a player’s value to his team in net points per 100 possessions.
Box Plus/Minus
The most popular regression model, likely because it’s displayed on Basketball-Reference, is Box Plus/Minus (BPM). It’s exactly as it sounds: all explanatory variables are box score statistics. Developed by Daniel Myers, BPM estimates value based on four five-year samples of “Bayesian Era” PI RAPM. This differs from, say, Backpicks‘s BPM, which is based on three-year samples of RAPM. There are multiple technical differences between the two, and the yearly leaderboard exhibit those differences. However, Myers’s model is likely the superior of the two, although we can’t be certain because its counterpart has no records of calculation details. But the defensive component in Myers’s appears far stronger than that of Backpicks‘s, and it’s safe to say the BPM available to the public is the strongest option for box-oriented metrics out there.
Augmented Plus/Minus
A less-recognized regression model, but one that makes an argument as one of basketball’s best, is Augmented Plus/Minus (AuPM). Developed by Backpicks founder Ben Taylor, it measures a player’s impact with the box score as well as plus/minus data. The explanatory variables were, described by Taylor, hand-picked, and evidently so. More obvious ones are a player’s traditional Plus/Minus, his On-Off Plus/Minus (team’s Net Rating with a player on the floor versus off the floor), and even Backpicks‘s BPM model, as well as teammate plus/minus data for team context. Then there are more separative variables like defensive rebounds and blocks per 48 minutes. This isn’t to say players with proficiency in defensive rebounding and shot-blocking are automatically more valuable, but as the introductory statistics course sets forth, correlation does not equal causation. AuPM was designed to “mimic” long-term PI RAPM, and the metric likely had greater explanatory abilities with those two statistics in the regression.
Real Plus/Minus
The aforementioned “other one-number metric” mentioned earlier, Real Plus/Minus (RPM) is Jerry Engelmann’s enigmatic take on blending the box score with plus/minus data to approximate long-term RAPM. The metric sets itself apart in that there are no real calculation details available to the public. All we know with certainty is that RPM is one more in a pile of box score/plus-minus hybrids. Subjected to the intuitive “third-eye,” RPM may not have the descriptive power of some of its successors on this list, but it’s renowned for its predictive power, fueling ESPN‘s yearly projections. RPM has also not been subjected to long-term retrodiction testing, or predicting one season with the previous season, to compare the predictive abilities of RPM to that of other major metrics. However, two things to consider are: RPM was developed not only by Engelmann but Steve Ilardi, another pioneer of RAPM, and the primary distributor of RPM is ESPN, one of the major sports networks in the world. Given the creators, distributors, and the details we have on RPM, it’s safely denoted as one of the greatest impact metrics available today.
Player Impact Plus/Minus
The most prominent “hybrid” metric, Player Impact Plus/Minus (PIPM), is also arguably the best. Provided by Basketball Index, the creation of Jacob Goldstein is based on fifteen years of Engelmann RAPM to approximate a player’s impact with the box score and “luck-adjusted” on-off ratings; those being on-off ratings for a player with adjustments made to external factors like opponent three-point percentages and teammate free-throw percentages: ones the player himself can’t control. The product of this was an extremely strong regression model with an 0.875 coefficient of determination, indicating a very strong predictive power between Goldstein’s explanatory variables and Engelmann RAPM. It’s for this reason that PIPM is recognized as one of, if not the, best impact metrics in the world, especially given the publicity of its regression details.
RAPTOR
The product of the math whizzes at FiveThirtyEight is quite the mouthful: Robust Alogirthm using Player Tracking and On-Off Ratings (RAPTOR). It is, once again, infused with the box score as well as luck-adjusted on-off ratings, but two distinct qualities set it apart. RAPTOR includes player tracking data as a part of its “box” component, with deeper explanatory power as to shot locations, difficulties, and tendencies. The other is RAPTOR’s base regression. While the impact metrics earlier in the list use Engelmann’s RAPM, RAPTOR uses Ryan Davis’s RAPM due to its availability that lines up with access to the NBA’s tracking data. RAPTOR is a very young metric, having been around for only one season, and is based on the least “reliable” response variable, being Davis RAPM in place of Engelmann RAPM (but this is for good reason, as stated earlier). RAPTOR certainly has the potential to improve and grow, as evident from the fluctuation of the metric’s forecasting throughout the bubble, considering its great pool of explanatory variables. I wouldn’t bet on the best of RAPTOR as having been seen just yet.
Player-Tracking Plus/Minus
Player-Tracking Plus/Minus (PT-PM) is one of the less recognized impact metrics, but certainly one of the most intriguing. It’s exactly as it sounds: calculated from (box and) player tracking data. The metric was created by Andrew Johnson in 2014, a time when SportsVU was the primary provider of tracking data for the NBA. Since then, Second Spectrum has taken over, but it shouldn’t cause any deficiencies to calculate PT-PM in the following seasons. Tracking data that made its way into the regression included “Passing Efficiency” (points created from passing per pass), turnovers per 100 touches, and contested rebounding percentages. The defensive component was more parsimonious, requiring fewer explanatory variables for great descriptive power: steals per 100 and opponent efficiency and the frequency at the rim. These public variables were taken from the beta version of the metric, but the results were very promising. There’s limited information on PT-PM in the last few seasons, but its replication would likely produce another great family of impact metrics.
—
So why take the time to invest in impact metrics to evaluate players? For one, they capture a lot of the information the human eye doesn’t, and they do it well. The philosophical premise of metrics like RAPM and its role as a base regression makes the large heap of impact metrics extremely valid, not only in principle but in practice. If we operate under a series of presumptions: a player is rostered to improve his team’s success, and teams succeed by accruing wins, and games are won by outscoring an opponent, then the “best” players have the greatest impacts on their teams’ point differentials. Now, there will always be limitations with impact metrics: they only capture a player’s value in a role-sensitive, team-sensitive context. If a player were to be traded midseason, his scores would fluctuate more than they would if he remained on the previous squad. But adding context to impact metrics through practices like film studies and partiality to more helpful information (like play-by-play data), we can draw the most accurate conclusions as to how players would perform in different environments.
Leave a Reply